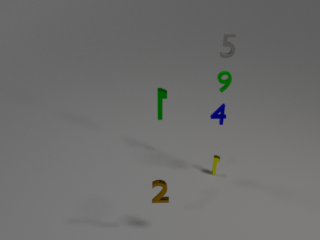Our research focuses on advancing the capabilities, efficiency, and reliability of
multimodal foundation models, particularly vision–language models (VLMs).
The projects below explore three complementary directions: improving the
computational efficiency of multimodal architectures, enhancing spatial and
semantic reasoning in training-free vision–language systems, and analyzing
the internal mechanisms that govern grounding, hallucination, and reasoning.
This work includes the development of token-efficient multimodal architectures
such as Delta-LLaVA, training-free segmentation methods that leverage
vision foundation models for improved spatial coherence, interpretability-driven
interventions for reducing hallucination in large VLMs, and new benchmarks such as
MARS for evaluating spatial–symbolic mathematical reasoning.
Together, these projects aim to better understand how multimodal models perceive,
reason, and compute over visual information while maintaining efficiency and
robustness.
The selected works below highlight contributions spanning model design,
training-free inference methods, mechanistic analysis of transformer dynamics,
and benchmark development for next-generation multimodal reasoning systems.
Delta-LLaVA: Base-then-Specialize Alignment for Token-Efficient Vision-Language Models
Projector design
Token-efficient MLLMs
144 visual tokens
Up to 55% throughput ↑
4–5× pretraining speedup
Multimodal Large Language Models (MLLMs) combine visual and textual representations to enable rich reasoning capabilities.
However, the high computational cost of processing dense visual tokens remains a major bottleneck. A critical component in this
pipeline is the visual projector, which bridges the vision encoder and the language model. Standard designs often employ a simple
multi-layer perceptron for direct token mapping, but this approach scales poorly with high-resolution inputs, introducing significant
redundancy. We present Delta-LLaVA, a token-efficient projector that employs a low-rank DeltaProjection to align
multi-level vision features into a compact subspace before further interaction. On top of this base alignment, lightweight Transformer
blocks act as specialization layers, capturing both global and local structure under constrained token budgets. Extensive experiments
and ablations demonstrate that this base-then-specialize design yields consistent gains across diverse benchmarks with only
144 tokens, highlighting the importance of token formation prior to scaling interaction capacity. With Delta-LLaVA,
inference throughput improves by up to 55%, while end-to-end training accelerates by nearly 4–5× in pretraining
and over 1.5× in finetuning, highlighting the dual benefits of our design in both efficiency and scalability.
DINO-Guided Attention for Training-Free CLIP Segmentation (DAP)
Training-free
Open-vocabulary segmentation
Patch-affinity guided attention
Boundary sharpening
Background suppression
Training-free open-vocabulary semantic segmentation aims to transfer vision-language models to dense prediction without task-specific
supervision. Despite recent progress, existing approaches often suffer from fragmented object regions, boundary leakage, and spurious
background activations, particularly under large domain shifts and fine-grained object structures.
We introduce Dense Aggregation via Proxies (DAP), a patch-affinity-guided attention mechanism that replaces the native
self-attention weights in the final CLIP visual transformer block with an externally induced patch affinity matrix. Patch affinities are
derived from external visual representations and optionally constrained to enforce region-level consistency, while CLIP’s value
projections, text–image alignment, and training-free setting remain unchanged. By propagating semantic affinity through
proxy-consistent neighborhoods, DAP promotes coherent object regions, sharper boundaries, and effective background suppression
without relying on additional training or explicit mask supervision. Extensive experiments across eight benchmarks and multiple CLIP
backbones demonstrate that DAP consistently improves over prior training-free methods, generalizes across diverse CLIP variants, and
scales favorably with model capacity.
Dual-Branch CLIP for Training-Free Open-Vocabulary Segmentation (DouC)
Training-free
Open-vocabulary segmentation
Dual-branch inference
Token gating + proxy attention
Logit-level fusion
0 learnable params
Open-vocabulary semantic segmentation requires assigning pixel-level semantic labels while supporting an open and unrestricted set of
categories. Training-free CLIP-based approaches preserve strong zero-shot generalization but typically rely on a single inference mechanism,
limiting their ability to jointly address unreliable local tokens and insufficient spatial coherence.
We propose DouC, a training-free dual-branch CLIP framework that decomposes dense prediction into two complementary components.
OG-CLIP improves patch-level reliability via lightweight, inference-time token gating, while FADE-CLIP injects external structural
priors through proxy attention guided by frozen vision foundation models. The two branches are fused at the logit level, enabling
local token reliability and structure-aware patch interactions to jointly influence final predictions, with optional instance-aware correction
applied as post-processing. DouC introduces no additional learnable parameters, requires no retraining, and preserves CLIP’s zero-shot
generalization. Extensive experiments across eight benchmarks and multiple CLIP backbones demonstrate that DouC consistently outperforms
prior training-free methods and scales favorably with model capacity.
Mitigating Hallucination via Mid-Layer Causal Geometry (CCM)
Training-free intervention
Hallucination mitigation
Mid-layer mechanism
Chebyshev-distance ordering
Concentric causal masking
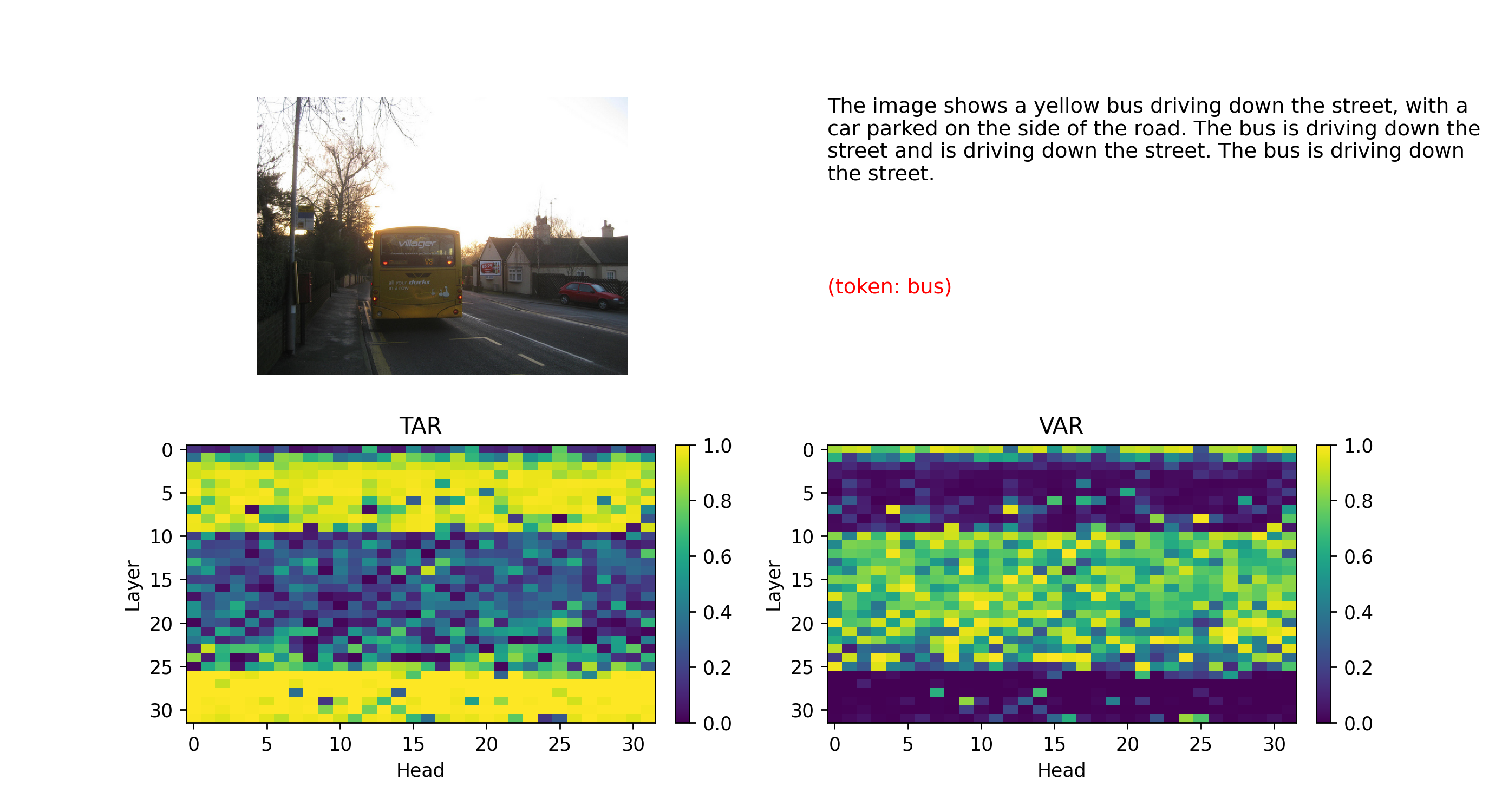
Token-level analysis (TAR/VAR)
Large vision–language models frequently suffer from object hallucination, generating descriptions that mention objects not present in the
input image. While prior work attempts to mitigate hallucination through decoding heuristics, reinforcement learning, or post-hoc filtering,
the internal layer-wise mechanisms behind this behavior remain poorly understood.
In this work, we analyze visual grounding dynamics across transformer layers and identify a middle-layer regime where visual evidence and
language priors compete during multimodal reasoning. Motivated by this observation, we propose a simple training-free intervention called
Concentric Causal Masking (CCM), which restructures visual token interactions using a Chebyshev-distance ordering while
preserving pretrained positional embeddings. Applied selectively within a band of middle transformer layers, CCM encourages attention from
generated tokens toward visual evidence during semantic consolidation. Extensive experiments across multiple benchmarks show that our
approach significantly reduces hallucination without retraining or architectural modification. Furthermore, token-level attention analysis
reveals that stabilizing attention dynamics in intermediate layers propagates improved grounding to later decoding stages, offering new
insights into the depth-dependent mechanisms underlying hallucination in LVLMs.
Seeing Numbers, Missing Logic — MARS: A Benchmark for Spatial–Symbolic Reasoning
VLM reasoning benchmark
Spatial–symbolic reasoning
Executable programs
3D synthetic scenes
Mathematical reasoning
Algorithmic evaluation
Mathematical reasoning in vision–language models (VLMs) demands more than visual perception—it requires structured integration of
grounding, symbolic manipulation, and procedural logic.
We introduce MARS (Mathematical and Relational Spatial Reasoning), a large-scale benchmark for visually grounded
mathematical reasoning built from executable functional programs rendered over structured 3D scenes.
Each question couples visual understanding (spatial relations, color, and reference anchoring) with symbolic operations such as
aggregation, ratio and mean computation, stack-based simulation, and iterative balancing. Across ten reasoning families,
overall accuracy remains modest: even the strongest models exhibit large variance across categories. Models excel at perceptual
and mean-based reasoning, yet collapse on algebraic composition and dynamic or graph-based processes. Smaller or purely
instruction-tuned systems perform near chance, confirming that neither scale nor generic finetuning suffices for executable reasoning.
These results reveal a sharp divide between grounded perception and algorithmic control: current VLMs recognize
what to attend to, but not how to compute over it.
By releasing executable question programs, reasoning traces, and reference-anchored scenes,
MARS establishes the first systematic benchmark for auditing spatial-symbolic
mathematical reasoning in multimodal foundation models.